数据初始准备就绪后,就需要对数据进行运算,就像做菜步骤中的炒菜环节!
Pandas数据运算
数据初始准备就绪后,就需要对数据进行运算,就像做菜步骤中的炒菜环节!
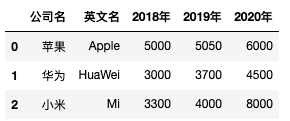
原始表格
算数运算
- 数据相加
+ - 数据相减
- - 数据相乘
* - 数据相除
/
案例:1
df['2018年'] + df['2019年']
结果如下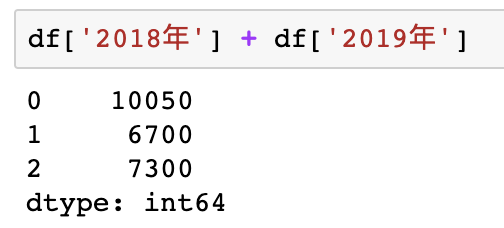
比较运算
- 大于
> - 小于
< - 不相同
!= - 相同
==
案例:1
df['2018年'] == df['2019年']
结果如下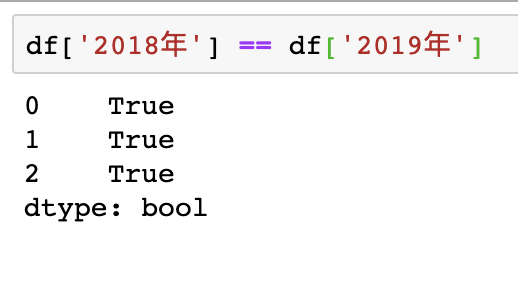
汇总运算
| 描述 | 语法 |
|---|---|
| 非空值计数 | df.count() |
| 求和 | df.sum() |
| 平均值 | df.mean() |
| 最大值 | df.max() |
| 最小值 | df.mix() |
| 中位数 | df.median() |
| 求众数 | df.mode() |
| 方差 | df.var() |
| 标准差 | df.std() |
| 求分位数 | df.quantile() |
注意
所有汇总运算默认都是以列为单位,单可以用 **df.运算方法(axis=1)** 参数改为行为单位进行运算例如 df.count(axis=1),并且可以指定行或者列df['指定'].count()
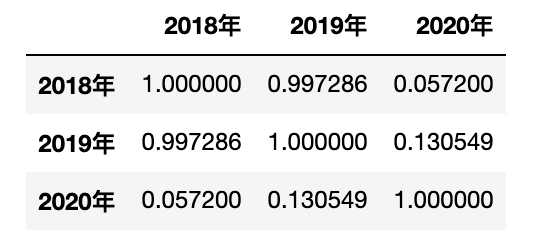
相关性运算
行量两者之间的关系之,比如衡量啤酒与尿布的关系值
1 | df['2018年'].corr(df['2019年']) #取 2008 年与 2019 年的关系值 |
取整体关系值
1 | df.corr() |
运行结果