数据挑选之后就好比挑出来菜品,接下来就开始切菜了。即对数值进行操作
替换
将 A 替换成 B, 可以用在异常替换处理、缺失值填充。
一对一替换
将某一块区域中的一个值全部替换为另一个值。例如年龄为240岁的,明显就是异常值,就可以替换成平均年龄33
1 | # 将 240 岁替换为 33 岁 |
思路: 县选中了年龄字段,然后调用 replace() 进行替换。
如果对整个表进行替换,比如表中所有缺失值进行替换, 这个使用用
replace()还不如用fillna()
1 | df.replace(np.NaN, 0) |
np.NaN 是对缺失值的统一标示
多对一替换
多个值替换为一个值, 例如把年龄240、260、280 替换为 33 岁。
1 | """将年龄为240、260、280 替换 33 岁""" |
多对多替换
比如年龄 240 替换为 29, 260 替换为 30, 280 替换为 31.
1 | df.replace({240:32, 260:33, 280:34}) |
排序
数值排序是按照具体数值大小进行排序,有升序有降序。
按单列排序
sort_values
1 | df.sort_values(by=['col'], ascending=False, na_position='first') |
ascending=False表示降序排列na_position='first'缺失值显示在最前面,默认显示在最后
按多列值进行排序
当第一列出现并列时,参考第二列,第二列并列参考第三列类推..
sort_values
1 | df.sort_values(by=['col1', 'col2'], ascending=[False, True]) |
ascending=False表示降序排列
数值排名
排名需要额外增加一列, 来储存排名从 1 开始
rank() 方法进行排名
- 参数1: ascending 指明升序排列还是降序排列,默认升序。
- 参数2: method 当出现并列情况的处理,如下表格所示。
method 参数说明:
| method | 说明 |
|---|---|
average |
当并列情况,按平均排名算 |
first |
按值在所有待排序书记中出现先后顺序排名 |
min |
并列情况,按最佳排名 |
max |
与 min 相反,取重复值对应的最大排名 |
1 | df['col'].rank(method='average') |
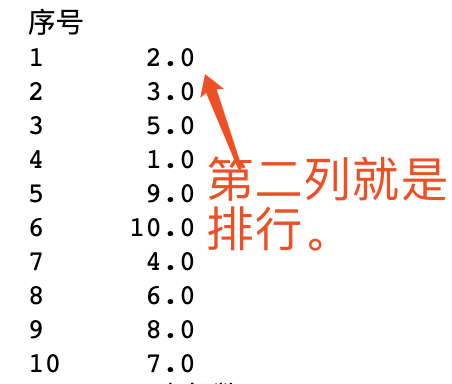
第二列就是该行的分数。
删除
将无用数据进行删除操作
删除列
可以使用
drop()方法,axis=1代表删除的是列
-
df.drop(['col1', 'col2'], axis=1)删除列axis=1 -
df.drop(df.columns[[4,5]], axis=1)列下标,删除第五列+第六列 -
df.drop(df.columns['col1', 'col2'])列名为参数
删除行
与删除行方法类似,
axis=0代表删除的是行
-
df.drop(['行1', '行2'], axis=0)该写法需要加上axis=0 -
df.drop(df.columns[[0,1]], axis=0)行下标,删除1、2行 -
df.drop(index=['行1','行2'])
删除特定行
删除满足条件的行, python 中会把不满足条件的数据筛选出来组合成新的数据源 从而实现过滤。
例如: 要删除年龄大于 40 的人员信息,我们将小于 40 岁的筛选出来组成新的数据源
1 | df[df['年龄'] < 40] |
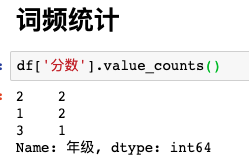
计数
指某一个值在数据中出现的次数。
- 统计次数
value_counts() - 统计频率
value_counts(normalize=True)
案例: 有如下成绩表

查找
查看数据表中是否包含某个值或某些值
- 针对指定列是否包含指定值
df['col'].isin([指定值1,指定值2]) - 针对全表是否包含指定值
df.isin([指定值1,指定值2])
区间分隔
比如你要按学生成绩将其分为多个组
pd.cut() 方法, 参数bins=[分隔区间]
1 | pd.cut(df['年龄'], bins=[0,3,6,10]) |
插入
用到
insert(下标,插入列名,[初始值])
初始表
插入身高列兵赋予初始值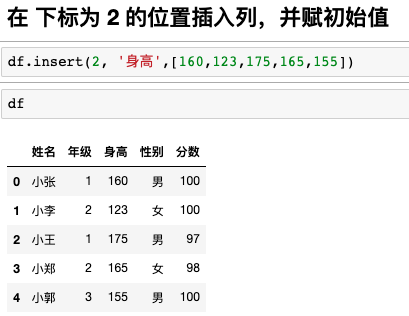
行列互换
特殊情况下需要用到
df.T
1 | df.T |

重塑为树形结构
默认是通过行与列来索引定位
将结构改为树形结构1
df.stack()
原始结构与效果结构如下
重塑之后
长宽表转换
宽表转换为长表
有的时候表过长了,就需要进行转换,例如如下情况,如果每年都会增加的情况下就很长。

这是一张公司平均每年产品售价表
我们需要将其转换为长表方便拓展与阅读
1 | df.melt( |
效果如下
长表转换为宽表
同上案例我们将其转回宽表
1 | df.pivot_table( |
apply() 与 applymap()
相当于
map函数,在此需要配合lambda使用
apply()
对某一个
column或row执行map操作
1 | """每个人分数+1""" |
applymap()
与 apply 用法相同,对每个元素都执行操作!