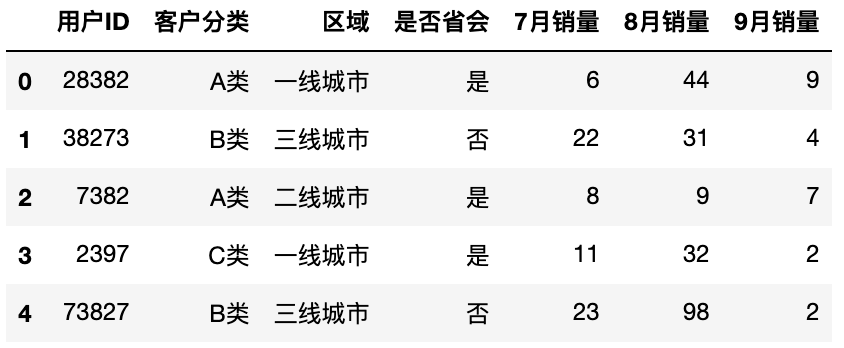
数据处理完毕后需要将处理结果进行分组与透视便于分析数据
原始表格如下
数据分组
数据分组就是根据一个或多个健将数据分成若干组,然后对分组后的数据分别进行汇总计算,并将汇总计算后的结果进行合并,被用作汇总计算的函数称为聚合函数。
按单列分组
按客户分类进行分组,再统计总数
1 | df.groupby('客户分类').count() |
运行结果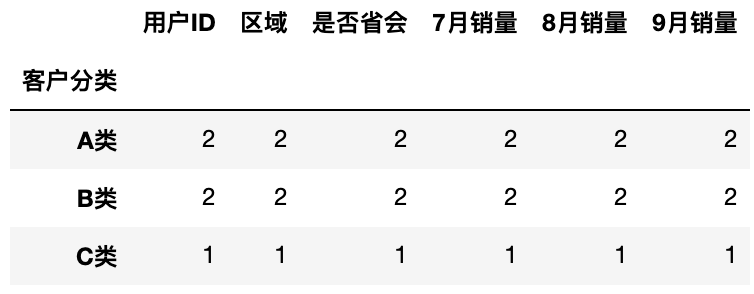
计算总数
1 | df.groupby('客户分类').sum() |
运行结果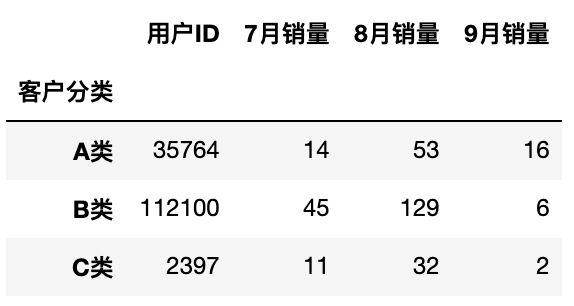
按客户分类分组,统计用户ID字段
1 | df.groupby('客户分类')['用户ID'].count() |
运行结果
按多列分组
1 | df.groupby(['客户分类','区域']).count() |
运行结果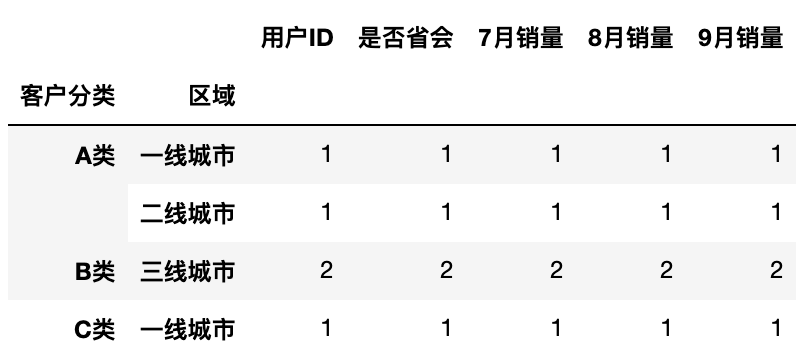
也可以按照多列进行分组, 只需要以列表的形式传给 groupby() 即可
分组后同时多种运算
比如按分类分组后,想看到总数与总和两个统计
aggregate()
1 | df.groupby('客户分类').aggregate(['count','sum']) |
结果如图,同时做出了2种统计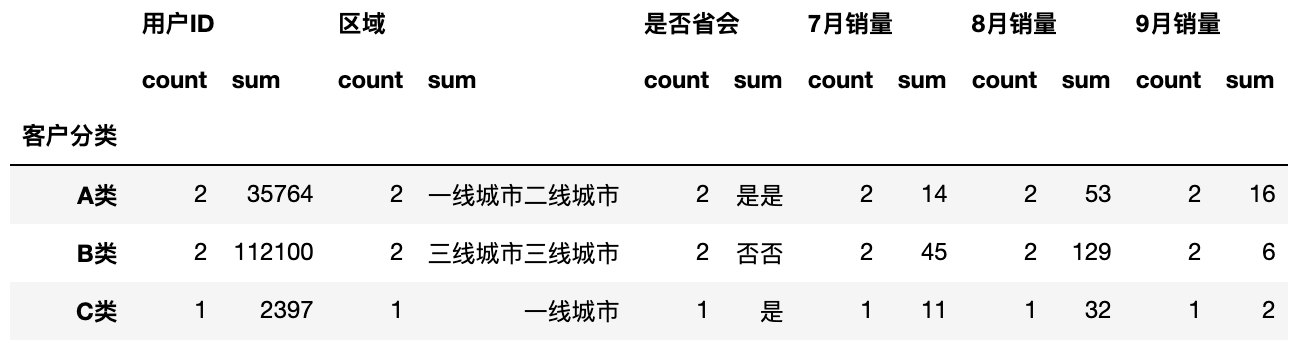
不同列做不同统计
先对客户分类, 在对不同字段进行不同的统计
1 | df.groupby('客户分类').aggregate({'用户ID':'count','7月销量':'sum','8月销量':'sum'}) |
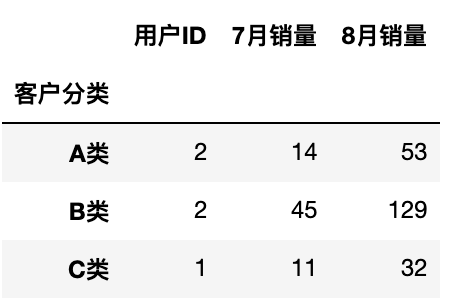
分组后重制索引
通常我们统计出之后为非标准的 DateFrame 格式,我们需要重制索引
reset_index()
1 | df.groupby('客户分类').sum().reset_index() |
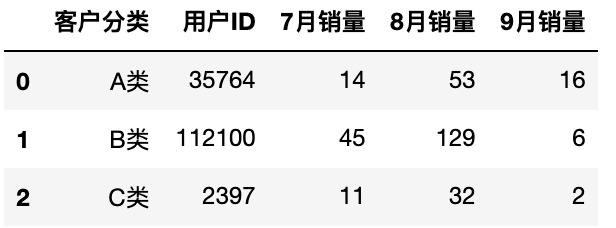
数据透视
数据透视与数据分组相似但不相同。
- 分组: 数据在 行 方向上不断拆分。
- 透视: 数据在 行与列 方向同时拆分。
通过 pivot_table() 方法对数据进行透视操作。
| 参数 | 作用 |
|---|---|
data |
数据表 |
values |
对应Excel中 值 的那个框 |
index |
对应Excel中 行 的那个框 |
columns |
对应Excel中 列 的那个框 |
aggfunc |
表示对 values 的计算类型 |
fill_value |
表示对空值的填充 |
margins |
是否显示合计列 |
dropna |
是否删除缺失值这一行 |
margins_name |
合计列的列名 |
客户分类作为 index,区域作为列,用户ID为值对值(用户ID)进行统计
1
pd.pivot_table(df, values='用户ID', columns='区域',index='客户分类',aggfunc='count')
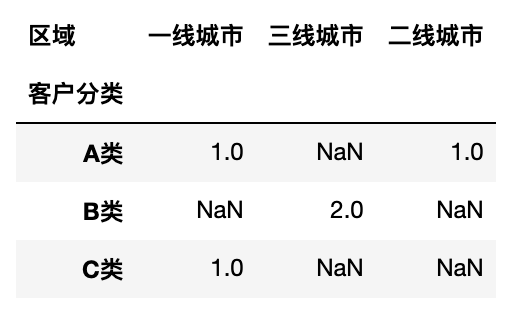
打开合计列功能
1
pd.pivot_table(df, values='用户ID', columns='区域',index='客户分类',aggfunc='count', margins=True)
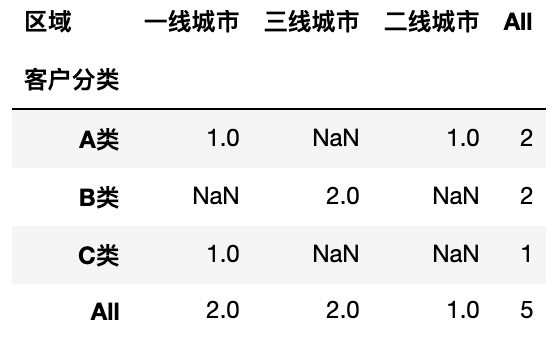
自定义 margins 合计名
1
pd.pivot_table(df, values='用户ID', columns='区域',index='客户分类',aggfunc='count', margins=True, margins_name='总计')
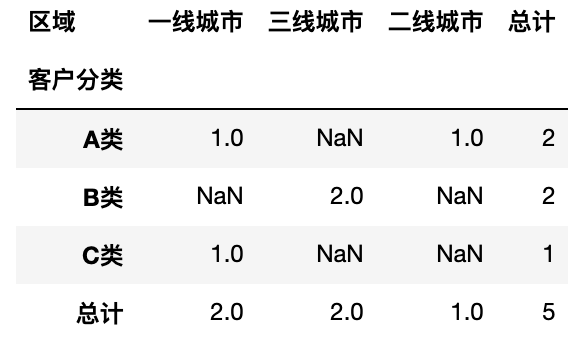
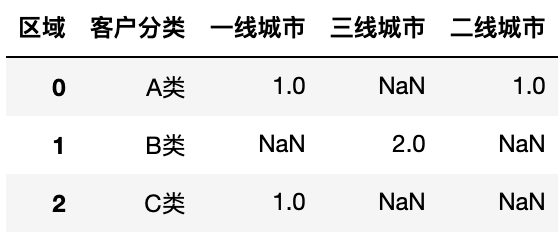
缺失值设置默认值
1
pd.pivot_table(df, values='用户ID', columns='区域',index='客户分类',aggfunc='count', margins=True, margins_name='总计', fill_value=0)
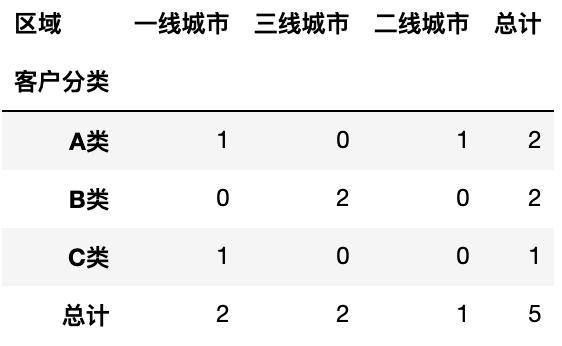
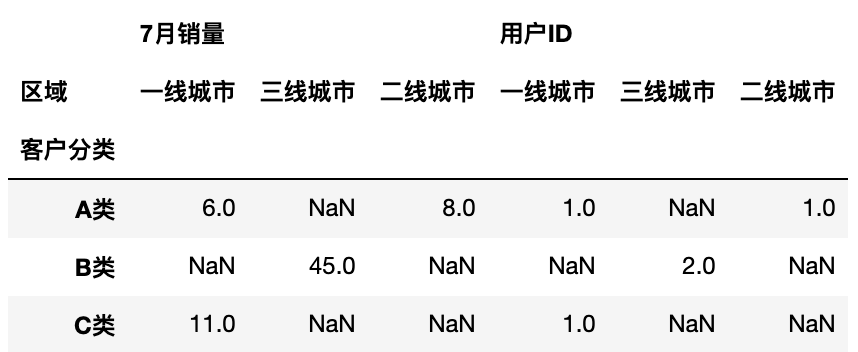
不同值进行不同统计运算
对ID进行计数, 销量求和1
pd.pivot_table(df, values=['用户ID','7月销量'],columns='区域', index='客户分类', aggfunc={'用户ID': 'count', '7月销量': sum})
重制索引
一半透视都是需要做重制索引的!1
pd.pivot_table(df, values='用户ID', columns='区域',index='客户分类', aggfunc='count').reset_index()