
MongoDB 聚合操作、子文档操作、AND与OR操作、性能优化
正则匹配
比如要查询包含
/^.*怒江.*$/的字段可以这样查询
1 | .find({'name': /^.*怒江.*$/}) |
聚合查询
聚合操作主要用于对数据的批量处理,往往将记录按条件分组以后,然后再进行一系列操作,例如,求最大值、最小值、平均值,求和等操作。聚合操作还能够对记录进行复杂的操作,主要用于数理统计和数据挖掘。在 MongoDB 中,聚合操作的输入是集合中的文档,输出可以是一个文档,也可以是多条文档。
三种方式如下
- 聚合管道
- 单目聚合
- MapReduce编程模型
聚合管道
简介
MongoDB 2.2 版本之后的功能,其作用是对文档进行过滤查询出复合条件的文档,并且对文档进行转换,改变文档的输出形式。
构建管道的语法如下db.COLLECTION_NAME.aggregate([{<stage>},...])
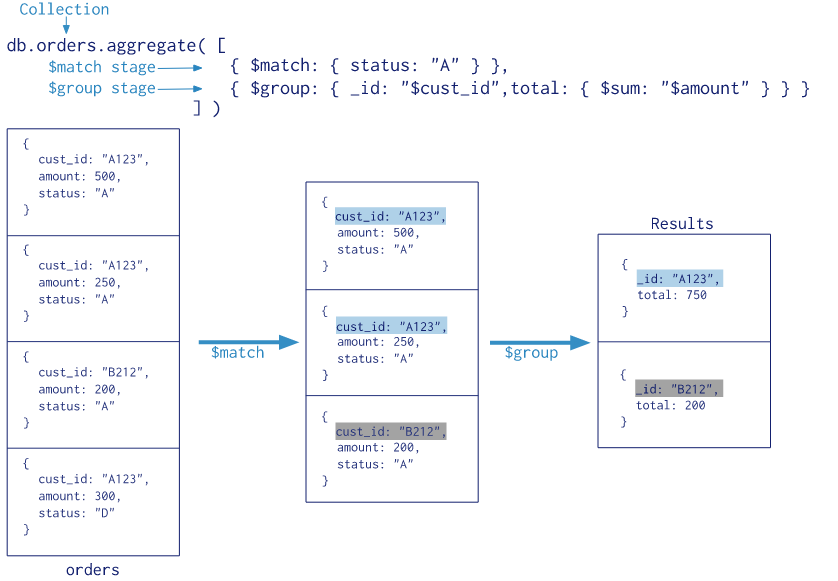
解释: $match 用于获取 status = “A” 的记录,然后将符合条件的记录送到下一阶段 $group 中进行分组求和计算,最后返回 Results。其中,$match、$group 都是阶段操作符,而阶段 $group 中用到的 $sum 是表达式操作符。
阶段操作符
| 语法 | 作用 |
|---|---|
$project |
修改文档的结构,可以用来重命名、增加或删除文档中的字段 |
$match |
用于过滤文档。用法类似于 find() 方法中的参数 |
$group |
将集合中的文档进行分组,可用于统计结果 |
$sort |
将集合中的文档进行排序 |
$limit |
限制返回的文档数量 |
$skip |
跳过指定数量的文档,并返回余下的文档 |
$unwind |
将文档中数组类型的字段拆分成多条,每条文档包含数组中的一个值 |
$project
修改文档结构,可以用来重命名、增删文档中字段等操作。
只返回 title 和 author 字段_id: 0 来禁止显示 _id1
db.article.aggregate([{$project:{_id:0, title:1, author:1 }}])
pages字段值加 10 并重命名1
2
3
4
5
6
7
8
9
10
11
12db.article.aggregate(
[
{
$project:{
_id:0,
title:1,
author:1,
newPages: {$add:["$Pages",10]}
}
}
]
)
$match
过滤文档,用法类似find()
- 在
$match中不能使用$where表达式操作符 - 如果
$match位于管道的第一个阶段,可以利用索引来提高查询效率 $match中使用$text操作符的话,只能位于管道的第一阶段$match尽量出现在管道的最前面,过滤出需要的数据,在后续的阶段中可以提高效率。
查询文档 pages 字段大于 5 的1
2
3
4
5
6
7db.article.aggregate(
[
{
$match: {"pages": {$gte: 5}}
}
]
).pretty()
$group
分组, 类似 mysql 的 group。
从 article 中得到每个 author 的文章数,并输入 author 和对应的文章数1
2
3
4
5
6
7db.article.aggregate(
[
{
$group: {_id: "$author", total: {$sum: 1}}
}
]
)
$sort
文档进行排序。升序 1, 倒序 -1
让集合 article 以 pages 升序排列1
db.article.aggregate([{$sort: {"pages": 1}}]).pretty()
$limit
限制返回的文档数量
返回集合 article 中前两条文档1
db.article.aggregate([{$limit: 2}]).pretty()
$skip
跳过指定数量的文档,并返回余下的文档。
跳过集合 article 中一条文档,输出剩下的文档1
db.article.aggregate([{$skip: 1}]).pretty()
$unwind
将文档中数组类型的字段拆分成多条,每条文档包含数组中的一个值。
-
$unwind所作的修改,只用于输出,不能改变原文档 -
$unwind参数数组字段为空或不存在时,待处理的文档将会被忽略,该文档将不会有任何输出 -
$unwind参数不是一个数组类型时,将会抛出异常
把集合 article 中 title=”MongoDB Aggregate” 的 tags 字段拆分1
2
3
4
5
6
7
8
9
10db.article.aggregate(
[
{
$match: {"title": "MongoDB Aggregate"}
},
{
$unwind: "$tags"
}
]
).pretty()
表达式操作符
表达式操作符有很多操作类型,其中最常用的有布尔管道聚合操作、集合操作、比较聚合操作、算术聚合操作、字符串聚合操作、数组聚合操作、日期聚合操作、条件聚合操作、数据类型聚合操作等。每种类型都有很多用法举例一些常用的。
- 布尔聚合
- 集合聚合
- 比较性聚合
- 算数聚合
- 字符串聚合
- 时间聚合
- 数组聚合
- 条件聚合
- 数据类型聚合
| 类型 | 语法 |
|---|---|
| 布尔 | $and |
| 布尔 | $or |
| 布尔 | $not |
| 集合操作 | $setEquals |
| 集合操作 | $setIntersection |
| 集合操作 | $setUnion |
| 集合操作 | $setDifference |
| 集合操作 | $setIsSubset |
| 集合操作 | $anyElementTrue |
| 集合操作 | $allElementsTrue |
| 比较 | $cmp |
| 比较 | $eq |
| 比较 | $gt |
| 比较 | $gte |
| 比较 | $lt |
| 比较 | $lte |
| 比较 | $ne |
| 比较 | $ne |
| 算术聚合 | $abs |
| 算术聚合 | $add |
| 算术聚合 | $ceil |
| 算术聚合 | $divide |
| 算术聚合 | $floor |
| 算术聚合 | $ln |
| 算术聚合 | $log |
| 算术聚合 | $log10 |
| 字符串聚合 | $concat |
| 字符串聚合 | $split |
聚合管道优化
- 将
$match和$sort放到管道的前面,可以给集合建立索引,来提高处理数据的效率。 - 可以用
$match、$limit、$skip对文档进行提前过滤,以减少后续处理文档的数量。 $sort+$match顺序优化 如果$match出现在$sort之后,优化器会自动把$match放到$sort前面
聚合管道限制
对聚合管道的限制主要是对 返回结果大小 和 内存 的限制。
返回结果大小
聚合结果返回的是一个文档,不能超过 16M,从 MongoDB 2.6版本以后,返回的结果可以是一个游标或者存储到集合中,返回的结果不受 16M 的限制。
内存
聚合管道的每个阶段最多只能用 100M 的内存,如果超过100M,会报错,如果需要处理大数据,可以使用 allowDiskUse 选项,存储到磁盘上。
AND与OR操作
AND
AND有2种写法
也就是我们平时用的隐形写法
1
db.getCollection('play_info').find({'字段1': '值1','字段2':'值2'})
显示AND方法
1
2
3db.getCollection('play_info').find(
{'$and': [{'字段1': '值1'},{'字段2':'值2'}]}
)必须使用显示AND的情况
在嵌套or的时候
1
2
3
4
5
6db.getCollection('play_info').find(
'$and':[
{'$or': [{'字段1': '值1'},{'字段2':'值2'}]},
{'$or': [{'字段1': '值1'},{'字段2':'值2'}]},
]
)
OR
OR 与显示AND的方法完全相同
1 | db.getCollection('play_info').find( |
子文档操作
Mongodb是Nosql,可以在字段中嵌套字段
例如 {'name': '小张', '爱好': {'运动':'篮球','文艺':'唱歌'}}
查找子文档数据
在查找子文档时需要使用 嵌入式文档名.嵌套字段名
案例
1 | db.getCollection('play_info').find({'字段1.嵌套字段': '值1'}) |
返回子文档数据
使用 $project来提取数据
数组字段
例如 {'name': '小张', '爱好': ['篮球','唱歌']}
查找保护篮球的爱好
1 | db.getCollection('play_info').find({'爱好': '篮球'}) |
查找不包含篮球的爱好,在其中运用上$ne
1 | db.getCollection('play_info').find( |